
How to evaluate Object Detection models for your custom dataset
Scaled YOLOv4 vs YOLOv5


It is a very exciting time in the space of object detection models in computer vision as different research groups compete with each other to provide better approaches. The race over here is to generate models which can deliver better results in the tradeoff between accuracy, speed of inference, and the size of the model, The rationale being that object detection models need to be deployed in edge devices where both computation resources and system memory are in short supply, at the same time performance in terms of accuracy and speed is highly desired. Since the advent of YOLO in 2016, multiple generations of improvements such as YOLOv3, YOLOv4, YOLOv5, and Scaled YOLOv4 have been suggested by researchers. While there is a lot of work that has been done in evaluating and bench-marking the performance of these models, the reality is that results vary across datasets. Hence, if you are thinking about deploying an object detection model in production, you really need to evaluate how each model performs in your environment on your specific data set. This article teaches you how you can go about doing that.
Previously, we wrote about how to train YOLOv5 on your custom dataset. The process of training any other model is very similar, and involves the following steps. Since this article focuses mainly on the evaluation, we will describe the training of the model in brief. Here are the rough steps that we have found useful in training a model. We have found Roboflow.com to be a great platform for doing end-to-end Machine Learning Operations (MLOps) for computer vision. These steps are based on using the Roboflow service, but can be easily replicated if you desire some other tooling.
Preparing the dataset: Upload your dataset at roboflow.com. That is as simple as uploading your images or your video. If you upload a video, Roboflow uses your browser’s capabilities to extract image sequences at the desired frame rate provided by you.
Annotating: Roboflow has recently introduced a great way of annotating a dataset, by picking one image at a time, drawing a bounding box, and specifying the text annotation. Alternatively, you can use other tools such as labelImg. Labelling is certainly one of the most human intensive steps in the machine learning pipeline and it is great to see roboflow take steps to make the labeling easier.
Preprocessing and Augmentation: Now that you have a labelled dataset, you can augment it by preprocessing and augmentation. In preprocessing, you apply some transformations to your images such as resizing, cropping, or making the image grayscale. By augmentation, you increase the diversity of your images by changing the brightness, changing the rotation, etc.
Training. Testing, Validation: Once you have your dataset ready, roboflow allows you to download the dataset in your desired format. You can then go through the training, testing, and validation steps using your preferred model on that dataset. Roboflow also allows you a way to request training, in which case they would take care of the training pipeline. One approach to train your models is to reuse example Google Colab notebooks that roboflow provides for Scaled YOLOv4 and YOLOv5.
Evaluation
Now let us jump into the evaluation part. Let us assume that we have two models to compare: Scaled YOLOv4 vs YOLOv5. We know that in theory Scaled YOLOV4 performs better on the COCO dataset, but we are unsure how it will perfor m in our specific environment and our dataset. Here are some ways by which we attempted to evaluate our models and understand which one is better. For each evaluation, we document how Scaled Yolov4 performed with respect to YOLOv5 on the Anki Vector Robot Dataset which we have used before. This dataset has been designed to allow one to train a model which can detect a Vector robot in the camera feed of another Vector robot. So, now let us examine how Scaled Yolov4 performs with respect to YOLO v5 against each of the following evaluation criteria.
Performance during training and test:
Time to train and run inference
Live performance of inference on a new video.
You can access the Jupyter notebooks we used for comparison of Scaled Yolov4 and Yolov5. All comparisons are made on training based of Tesla T4 GPU. Training of the model was continued till steady mAP@.5 was achieved. In the case of Yolov5, mAP@.5 was stable after 40 epochs, and hence training was completed in 50 epochs. However, for Scaled Yolov4, there was a dip in mAP@.5 at the 50th epoch, and hence training was continued till 100 epochs at which point mAP@.5 was stable. Here are some more details of our evaluation.
Performance during training and tes

Table 1: Comparison of the performance of Scaled Yolov4 vs YOLOv5

The verdict from these set of results is clear, Scaled Yolov4 wins by a small bit.
Time to train and run inference

Table 2: Comparison of time to train and time to do inference.

Scaled Yolov4 certainly takes more time for both training and inference. Note that training is expected to be a bit more expensive because of double the number of epochs.
Live performance of inference on a new video: Let us examine how the model performs on a new dataset and check if what the model learned can be transferred to a new setting. This capability is also termed as transfer learning in machine learning terminology. To do this, we captured a video from Vector with the other Vector amidst a background of kids toys. We did inference with both Scaled Yolov4 and Yolov5. Here are the output videos of the two cases. In both cases, we classify that the boundary box correctly identifies Vector if a threshold of 0.5 is crossed. First let's watch the video of inference with Scaled Yolov4
Now let’s watch the video with Yolov5
Scaled Yolov4 seems to perform better than Yolov5. You would notice that Yolov5 concludes that there are 2 Vectors at several times, while the identification in Scaled Yolov4 is neat and steady. Scaled Yolov4 does miss identifying Vector for a fraction of seconds, but it would seem that the inference is better. We crowdsourced the effort of trying to distinguish which model performed better. We set up polls on Facebook, Twitter, And Reddit with links to the above video outputs from the two models, and requested people to vote for which was better. The results are in the figure below. We received 13 votes across all social media, and except for one vote, everyone was in unanimous agreement that Scaled YOLOv4 performed better. We now have ample proof that both statistically and from a human preference point of view, Scaled YOLOv4 did better.
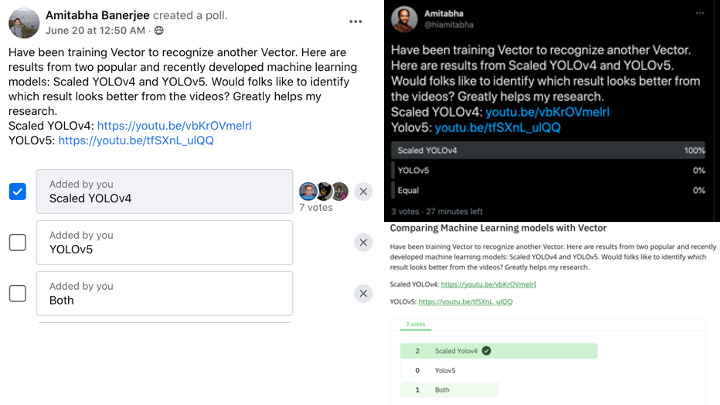
Conclusion
After this study, we can conclude that Scaled Yolov4 seems to give better results. We can now deploy this model in production. However, one of the important jobs of a ML engineer is to continuously monitor and retrain one's models and examine the performance of models for newer samples of data.
Epilogue
Please watch out this space for more articles on steps to do the same. Also, subscribe to this newsletter for more content directly delivered to your inbox. If you do not want to miss premium content from us, please consider buying a paid subscription.