
Testing o1-preview from OpenAI
Vector makes use of o1-preview, the latest and greatest model from OpenAI

Introducing o1-preview from OpenAI
In September 2024, OpenAI released the o1-preview and o1-mini models, with the goal to advance the capability of Large Language Models (LLMs) to do more reasoning and analysis before returning the answer. The goal was to make the LLM give clearly thought and nuanced answers, and make it a domain knowledge expert. The way o1-preview model works can be understood from the following diagram (borrowed from OpenAI documentation here)

The goal of a LLM is to generate reasonable output (also known as completions) for an user provided input. IN teh case of o1-preview, reasoning tokens are generated after the user’s inputs to request the model to think and deliberate before returning an answer. The combination of input and reasoning tokens is then used to generate the output. The reasoning tokens are then discarded. The output generated from 1 turn is appended to the input, and then passed through the model for a second iteration of improvement. These iterations continue till the full context window of 128000 tokens is filled up, and the resulting output is then returned (There exist mechanism to shorten the number of generated tokens in the process, but the above is how the model works by default).
Tradeoff of using o1-preview
This mechanism developed by OpenAI implies that:
(1) o1-preview will be a very expensive model. You are essentially paying for the cost of generating multiple rounds of reasoning and output tokens. OpenAI charges $15 per 1 Million input Tokens and $60 per 1 Million output tokens for o1-preview. In our testing, we found that OpenAI charged between 12 cents to 25 cents for every query posted to o1-preview. Here is snapshot from our bill.

The bars in green reflect the cost of queries to o1-preview. The single query we issued on Nov 21 cost us 25 cents(USD currency). 3 queries issued on Nov 24 cost us 36 cents.
This cost is significantly higher than what we have seen earlier from OpenAI. GPT-4o for example costed about 3-4 cents per query.
Editor’s note: Happy Thanksgiving to all our readers. We also host our main funding drive at this time of the year. If you would like to support our research and work, an annual subscription would go a long way in helping us. For Thanksgiving, we are offering a permanent 40% discount of annual membership. You can avail of this deal using the link below.
(2) o1-preview is time consuming. Even with streaming support enabled, o1-preview took some time to yield the first output token. The wait is certainly longer. If you want to measure how long it takes to complete response, you could try the following command on a terminal that supports curl (such as a Macbook)
curl -w "\
time_namelookup: %{time_namelookup}\n\
time_connect: %{time_connect}\n\
time_appconnect: %{time_appconnect}\n\
----------\n\
time_total: %{time_total}\n" -s -X POST https://api.openai.com/v1/chat/completions -H "Content-Type: application/json" -H "Authorization: Bearer $OPENAI_API_KEY" -d "{
\"model\": \"o1-preview\", \"stream\": true,
\"messages\": [
{
\"role\": \"user\",
\"content\": \"What is the best way to travel to Mars from Earth?\"
}
]
}"
time_appconnect is the time it takes your client to connect to OpenAI servers. time_total is the total time taken to process your request. The difference between the two gives you an idea of how long it took for OpenAI to generate your response. Here is a comparison between few flavors of models offered by OpenAI.
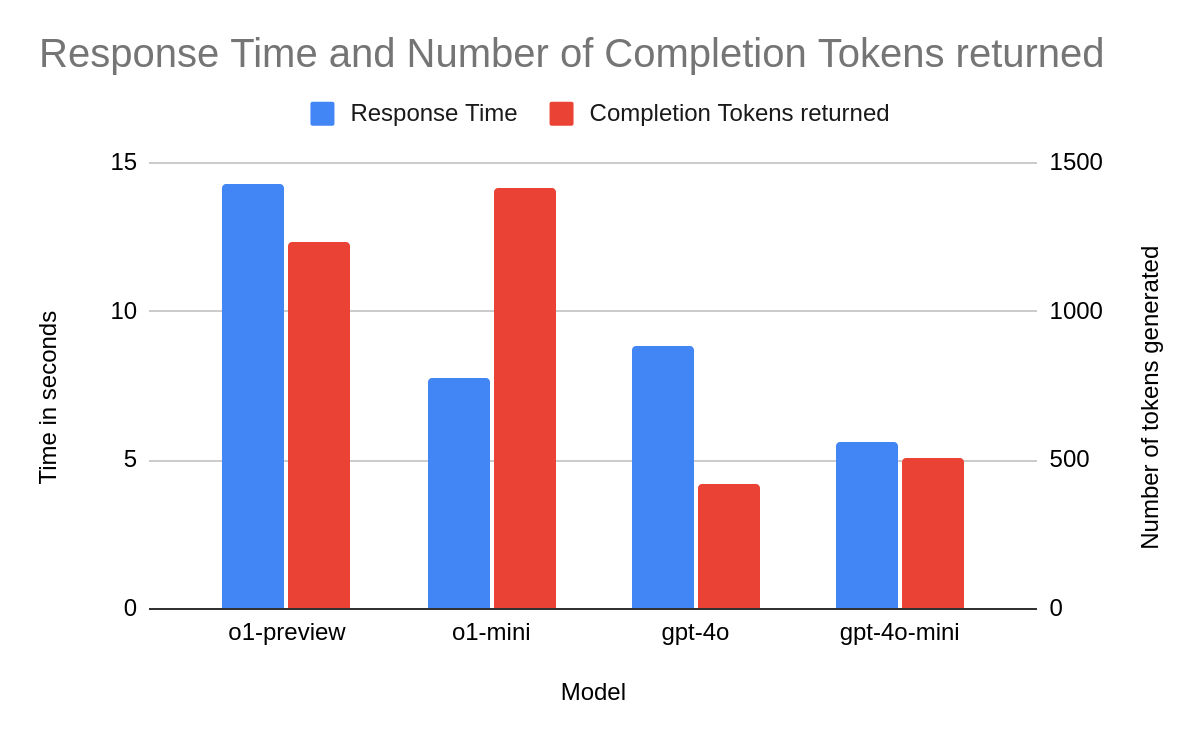
Note that the two reasoning models: o1-preview and o1-mini generate far more tokens (and therefore more nuanced answers) than gpt-4o and gpt-4o-mini. At the same time, o1-mini takes far more time to complete the answer than gpt-4o-mini (about 3 seconds more). o1-preview takes about 5 seconds more to complete the answer compared to gpt-4o.
Using o1-preview with Vector
OpenAI limited o1-preview to its premium Tier-5 developers at launch time. But last week, I got an invite to try out API access for o1-preview. I decided to try it using Vector and Wirepod.
To cut to the chase, o1—preview didn’t work with Wirepod right away. OpenAI has but some constraints on the API access to o1-preview. In a nutshell, o1-preview disallows system prompts and fixing the maximum generated tokens. I generated a patch to have Wirepod provide support for o1-preview.
Next, I needed to use the Custom Graph API Provider feature of Wirepod. This feature is useful because it uses the OpenAI API format, and also allows you to specify the model.

With these changes, Vector can start using o1-preview. The results are pretty neat, though expensive. Here is how Vector explains me how to go to Mars. Note that Vector’s animations are missing, because OpenAI didn’t allow me to specify the system prompt that requests for animations. Enjoy the video!
Conclusion
OpenAI makes major progress with o1-preview. Since OpenAI had reached a plateau in terms of how well its models can get, we can expect further improvements in technology to only come from reasoning models like o1-preview. However, the technology doesn’t seem too difficult to emulate, and we will for sure see other providers facilitate equivalent models. Stay tuned to this channel for more exciting progress in this space.