
YOLOv8 is the new beast in town
Let's compare it with previous versions of YOLO

What’s YOLO?
We have discussed the You Only Look Once (YOLO) series of models several times, particularly because object detection, image segmentation, and image classification are key tasks that a robot must effectively perform to excel in real-world tasks. YOLO models have been shown to be excel at the tradeoff between speed and accuracy. In previous articles, we have discussed the process of preparing a dataset and training a YOLO model. We have also discussed the ways to scientifically evaluate a Machine Learning (ML) model and compare it with other similarly trained models using Key Perfomance Indicators (KPIs). We also have a technical course taking you through the journey of Machine Learning from Scratch to Production.
YOLOv8
This article specifically compares the latest YOLO model released by Ultralytics: YOLOv8 with respect to previous generation of models, using the techniques and approaches described in previous articles. Our evaluation is based on our favorite dataset: the Anki vector dataset which we have made publicly available at Roboflow. This dataset comprises of 590 images of training, 61 for validation, and 30 for test, and has proven to be very useful in terms of training a YOLO model and using it for detecting another Vector robot.
Let’s compare
Each YOLO model is trained to 50 epochs. For YOLOv5, YOLOv7, and YOLOv8, we used the medium sized models (ending with m). Since our dataset is small, 50 epochs are more than sufficient to reach steady state. Here is how they compare for several metrics:
Accuracy:
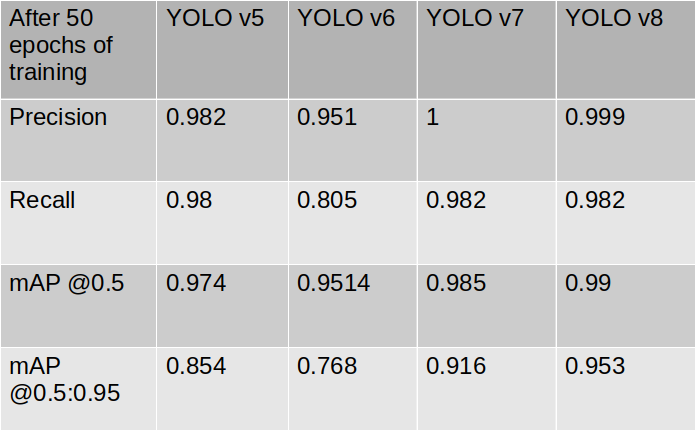
Accuracy results of training YOLO* models

Specifically for object detection, mAP@0.5 or mAP@0.5:0.95 are great KPIs to focus on… intuitively they represent how accurate the bounding boxes are formed around the detected object. It can be seen that in both of these metrics, YOLOv8 performs much better than its predecessor YOLOv7
Time to Train:

All training was done in a Google Colab environment with nVidia Tesla T4 GPUs. The medium sized model of YOLOv8 is a bit smaller than YOLOv7; that leads to a bit faster training time. It is important to note that a model with smaller number of parameters is able to perform better in terms of mAP scores over our dataset.
Inference Time:

Comparison of Inference Time across YOLO models

The smaller sized model leads to much faster time for detecting objects. In fact YOLOv8 performs much faster than any of its predecessors… a major 3 ms jump over inference. Getting better accuracy as well as better inference time is a great leap, and we are very curious to see how it performs on other datasets.
Application to a live setting:
We used YOLOv8 on the same video we evaluated our previous models on. This video is taken from Vector’s camera as he looks at another Vector robot. Let us checkout out how YOLOv8 performs in practice.
You might want to compare it with how YOLOv7 worked in practice.
Which model do you think did better? Please help make this topic interesting by voting below. You can also check out a split screen comparison here.
In Conclusion
As we have reiterated in previous posts - every Machine Learning model needs to be evaluated specifically to the use case, and for the key metrics that are of interest. For our use case - allowing a Vector to detect another Vector, YOLOv8 definitely shows considerable improvement. We look forward to see how other users find YOLOv8 relative to previous YOLO models. If you have been users of YOLO models, and would like to share some insights, please drop a note in the comments below.