
YOLOv9 is here
The next in the YOLO series of models has finally arrived.

Background
YOLO (You Only Look Once) is a class of Machine Learning models that facilitate object detection and image classification with great speed and accuracy. YOLO is very popular in applications that require real-time object detection such as robots needing to understand the environment around them.
Our posts describing how to let a Vector robot detect another Vector robot (using the Python SDK) using the YOLO have been very popular… In the past we have written a comparison between YOLOv4 vs YOLOv5, YOLOv5 vs YOLOv6 vs YOLOv7, and on YOLOv8. This article continues the series exploring the recently released YOLOv9.
YOLOv9
The latest update to the YOLO models: YOLOv9 was released on 21st February 2024. The YOLOv9 academic paper mentions an accuracy improvement ranging between 2-3% compared to previous versions of object detection models (for similarly sized models) on the MS COCO benchmark. While 2-3% might not seem a lot, it is actually a big deal because many classes of object detection models have been stuck at the 50% accuracy level on MS COCO.
It is also important to remember here that the size of the model determines the computation cost for object detection… therefore an apples-to-apples comparison can be made only between two models of the same size. For robotic systems, the preference would be to have great accuracy on the small to medium sized models. In this regard, YOLO models have made great improvements over the years, the table below shows how the mAP 50:95 score (Mean Average Precision between 50-95% detection, higher is better) has improved from YOLOv5 to YOLOv9, while the size of the model has shrinked. Data in the table has been extracted from Table 1 in the YOLOv9 paper. YOLOv9 is a great model just in terms of the number of parameters of the model… this directly reduces the compute time to do training and run inference.

Let’s train YOLOv9 for Anki Vector
However, just because that a model is proven to achieve better mAP scores on the MS COCO dataset, it doesn’t mean that it will do better for your specific use case… you need to try it out the new model and identify yourself that it is indeed better for your use case. Thanks to our friends at Roboflow, fine-tuning a YOLOv9 model on a custom dataset is very easy and cheap to do on a Google Colab Instance. Specifically for our specific use case, we want to train a YOLOv9 model that can help the Vector robot detect another Vector robot. We have a notebook which you can run yourself and train the YOLOv9 model on a Google Colab instance with the Vector dataset (which we have made publicly available as well at Roboflow). The Vector dataset comprises of 590 images of training, 61 for validation, and 30 for test, and has proven to be very useful in terms of training a YOLO model and using it for detecting another Vector robot.
Having fine-tuned the YOLOv9 model, we can compare it with other YOLO models which have been fine-tuned on the same dataset. The following video shows how the results from each YOLO model (medium sized configurations chosen akin to the table above) for a camera feed from Vector with another Vector robot in the vicinity which the YOLO model is trying to identify. Enjoy the video.
Editor’s note: If you are enjoying our newsletter, please consider donating a gift subscription to a loved one. We depend heavily on word of mouth advertising for our newsletter.
Rating the model
Once we have the results from each model, we can make a decision on which model was best for our use case. There are many ways of evaluating the performance of a model during inference. Let’s discuss some of these:
Key Performance Indicators for Training. The following tables compare some Key Performance Indicators (KPIs) for the different YOLO models. If you wish to understand these KPIs better, a previous post explores this topic in considerable depth.

Key Performance Indicators (KPIs) after training YOLO models on the Anki Vector dataset From the above table, we see that YOLOv9 achieves the same accuracy metrics after 50 iterations of training compared to YOLOv8. In other words, there is no more accuracy gain by switching from YOLOv8 to YOLOv9 for this particular dataset.

Time to train different YOLO models to 50 epochs YOLOv9 being a smaller model, trains faster, and therefore significantly beats YOLOv8 in training speed. In otehr words, if the time to train or equivalently the cost of training a model were a limited resource, then one would go with training a YOLOv9 model.
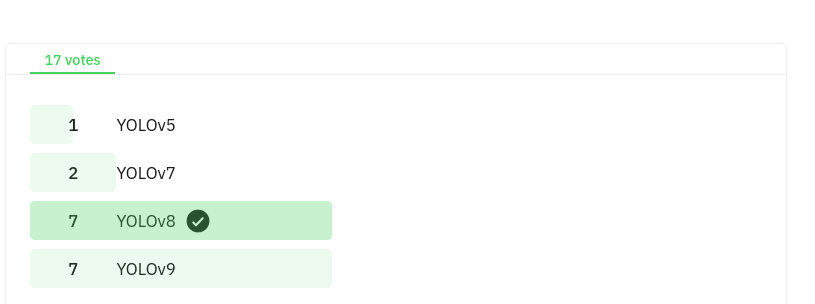
Input from users inspecting the Inference output: To detect how well the models perform while running inference, we poll the consumers of the use case, and get their feedback on which model is better. As an example, we posted the above video (comparing four YOLOs: YOLOv5, YOLOv7, YOLOv8, and YOLOv9) on (i) Vector’s Reddit channel and (ii) on Twitter, and asked users to rate which model was best. 17 votes were cast on Reddit, and 4 on Twitter. Results are in the figures below. It is clear that users are split between YOLOv8 and YOLOv9… indicating that people would perceive both models as very close to each other, and therefore there is no reason to prefer YOLOv9 over YOLOv8 just for better inference.

Results of Reddit Poll 
Results of Twitter Poll



Conclusion
YOLOv9 is out, but a newer model doesn’t mean a better model. We see that our specific use case, YOLOv9 is essentially a tie with YOLOv8. Hence, you need to evaluate any new model yourself. In future articles, we will focus on the key ingredients to training a YOLOv9 model. Meanwhile, if you got a chance to play with our YOLOv9 notebook, please comment your experiences below.